はじめに
Nutanixの主要なコンポーネントについて解説します。
トラブルシューティングなどする場合に、どうしてもコンポーネントの役割を抑えていないと解決が難しい場合が多々あります。
コンポーネント超概要
あまり馴染みのない方向けにざっくりと各コンポーネントの概要を整理しました。
赤字のコンポーネントは特に主要なものとなります。あくまでも管理人の主観によるものです。
- Stargate:I/Oの管理
- Cassandra:メタデータ(※1)管理
※1:ブロック(データ格納の最小単位)が、どのクラスターの、どのノードの、どのディスクに格納されているかを管理するデータのこと - Medusa:Cassandraにアクセスするためのインタフェース
- Zookeeper:クラスターの構成管理
- Zeus:Zookeeperにアクセスするためのインタフェース
- Curator:不要なデータのクリーンアップ
- Prism:UIとAPIの提供
- Genesis:クラスターコンポーネントのサービスマネージャー
- Chronos:ジョブスケジューラー
- Ergon:タスク管理
- Pithos:vDiskの構成管理
- Cerebro:レプリケーションやDR(Disaster Recovery)の管理
- Lazan:ホットスポット回避
- Arithmos:統計情報管理
- Mantle:ディスクの暗号鍵管理(Data at Rest Encryption)
CVMでgenesis statusを実行していただくとわかりますが、他にも様々なサービスが起動しています。しかしながら、全てのサービスについて公開情報がないため、ここでは割愛します。管理人が教えてほしいくらいです。
CVM上で動作するコンポーネントの相関図
主要なコンポーネントの概要を押さえたら、次に相関図を覚えておくと良いです。
Nutanix bibleなどに掲載されています。
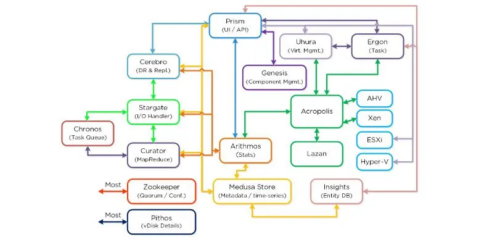
各コンポーネントの解説
コンポーネントによっては相互依存関係があるものとそうではないものがあります。
依存性がないものについては[独]とコンポーネントの右横に記載することにします。
また、全てのノードで動作するコンポーネントについては[全]とします。書かれていないコンポーネントも基本的に全てのノードで動作しているはずです。気になる方はallssh “genesis status” | grep “サービス名”で、全てのCVMのサービスを確認してみてください。
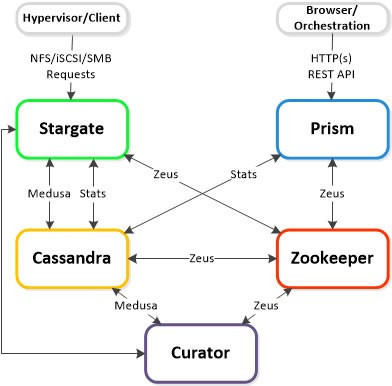
Stargate [全]
- 全てのデータ管理とI/Oオペレーションに責任を持ち、ハイパーバイザーからのメインインターフェイスとなる。
- ローカルI/Oを担うため、クラスターの全てのノードで動作。
- 全ての読み書き要求は、vSwitchを介して、そのノードで実行されているStargateプロセスに送信される。
- Stargateはメタデータの収集をMedusaに依存。
- クラスタ構成データの収集をZeusに依存。
Cassandra [全]
- ゲストVMのデータに関する全てのメタデータを保存する、高機能でスケーラブルな分散データベース。
- Apache cassandraを大規模修正したものに基づいた、分散リング様の方法で、クラスターメタデータを全て保持・管理する。
- 厳密な整合性を施工するためにPaxosアルゴリズムを使用。
- 全てのクラスターのノードで動作。これらのノードはgosship protocolを使用して1秒に1回相互に通信を行い、全ての状態が最新であることを保証。
- Medusaと呼ばれるインタフェース経由でアクセスする。
- ファイルのサイズが512Kに達すると、クラスターはデータを保持するvDiskを作成。
Cassandraについてかなり細かい仕様を記載したドキュメントもがありました。参考に。

Medusa
- Medusaは、cassandraのインターフェース。
- このメタデータを保持するデータベースの前に位置するNutanixの抽象化レイヤである。
- Medusaはホストとホスティング仮想マシンのデータを保存して追跡。
- StargateとCuratorはMedusaを介してCassandraと通信する。
- MedusaはVMのマスター・データのレプリカを追跡し、ノードが故障した場合でもデータを安全に保つ。
- データベースはクラスタ内の全ノードに分散され、Apache Cassandraの改良版を使用する。
Zookeeper [独] [全]
- Apache Zookeeperに基づいた、ホスト、IPアドレス、状態、その他を含むクラスターの構成情報を全て保持する。
- クラスター適用される冗長性係数(Redundancy Factorのこと)に応じて、3つまたは5つのノードで実行される。そのうちの1つはリーダとして選出される。リーダは全てのリクエストを受信し、他の2つのノードと連携と取る。
- リーダがレスポンスに失敗すると、新しいリーダが自動的に選出される。
- 依存関係がないため、他のクラスターコンポーネントを実行しなくても起動できる。
- Zeusと呼ばれるインタフェース経由でアクセス。
Zeus
- ZeusはZookeeperのインターフェースで、nutanixクラスタに関する他のコンポーネントへの情報アクセスを提供。
- Zeusは、他のすべてのコンポーネントがクラスタ構成にアクセスするために使用するNutanixライブラリ。
- すべてのクラスタ情報を格納。
- クラスタ構成には、クラスタ内の物理コンポーネント(ノード、ディスク)と論理コンポーネント(ストレージコンテナ)に関する情報を含む。
- ZeusはノードのIPアドレス、容量、RF-2やRF-3のようなデータレプリケーションルールを追跡。
Curator [全]
- ディスクバランシングと情報ライフサイクル管理を行う。
- Curatorはクラスタの各ノード上で実行され、ストレージ上のメタデータとVMのマスター・データを追跡する。
- Curatorマスターノードは、定期的にメタデータ・データベースをスキャンし、Stargateまたは他のコンポーネントが実行すべきクリーンアップおよび最適化タスクを識別。
- メタデータの分析は、MapReduce アルゴリズムを使用して、他の Curator ノードで共有。
- Curatorは、どのノードが利用可能かを知るためにZeusに依存し、メタデータを収集するためにMedusaに依存する。その分析に基づいて、Stargateにコマンドを送る。
- タスクとジョブの委譲を管理するCuratorマスターノードによってコントロールされる。
Curatorについては更に細かく見ていきたいと思います。
Curatorには大まかに2つのscanタイプがあります。細かく見ると3つあります。
Partial Scans
- 情報ライフサイクルマネジメント
- スナップショットチェーンの切断
- 重複排除されていないto_removeとマークされたデータを削除する
- ブロックアウェアネスを修正
- 過剰に複製されたデータ、もしくは過少に複製されたデータを削除もしくは複製する
- 前回のpartial scan完了後から1時間後に実行される
Full Scans
- ディスク上の重複排除
- 自身のタイマーがあり、それに基づき実行(特定の時間に実施するわけではない)
- 前回のfull scan完了後から6時間後に実行される
Triggerd Scans
- ILM:hot tierがフルになった時、cold tierにデータを排出するためにILMスキャンが実行される
- Disk Failure:ディスク障害時、レプリカの数が少ないデータが複製される
- Node Failure:障害が発生したノードにレプリカがあった全てのディスクから、データをレプリケート
- User:手動実行
Curator Scanを手動で行う方法を紹介しています。
[Nutanix]Curator ScanをCuratorページから実行してみた
はじめにCLIコマンドでも実行可能なCurator Scanを、Curatorページから実行してみました。お断りこちら、あくまでも参考程度で見ていただくようお願いします。Curator Masterの特定任意のCVMにnutanixユーザー...
liberation-of-se-like-slaves.net
2025.04.12
Prism [全]
- UIやAPIを提供。
- Nutanixクラスターを構築、監視するためのコンポーネントや管理機能のための管理ゲートウェイ、nCLI、HTML5 UI、REST APIを含む。
- 全てのクラスターのノードで動作し、クラスターの全てのコンポーネント用に選出されたリーダーを使用。
Genesis [独] [全]
- 各々のノードで動作するプロセスであり、初期構成情報を含む、開始/終了/その他のあらゆるサービスのインタラクションに対して責任を持つ。
- クラスター内で独立して動作するプロセスであり、クラスターが構築されていること、動作していることを要求しない。
- Zookeeperが動作していることが唯一の動作するための必要条件。
- cluster_initやcluster_statusページはGenesisプロセスによって表示される。
Chronos [全]
- Curatorのスキャンの結果得られたジョブやタスクを受け取り、ノード間でタスクをスケジューリング/スロットリングする役割を担っています。
- 各ノード上で実行され、選出されたChronosマスターがタスクとジョブの委譲に責任を持ち、Curatorマスターと同じノード上で実行されます。
Ergon
- 動作している、スタックしているタスクを開始したり、中止したりすることに責任を持つ。
- 必要に応じて手動でタスクを実行/中止する場合も同様。
Pithos
- vDisk(DSF File)の構成データについて責任を持つ。
- 全てのノードで動作しCassandraの最上位に組み込まれている。
Cerebro [全]
- DSF のレプリケーション(Replication Factorの係数で指定した数だけ、ローカルに書き込んだデータが他のノードで複製されます)と DR 機能を担当する。
- 保護ドメインの設定に従って、スケジュールされた自動スナップショットの取得を担当する。
- スナップショットのスケジューリング、リモートサイトへのレプリケーション、サイトの移行/フェイルオーバーも担当する。
- Nutanixクラスタの各ノードで実行され、すべてのノードがリモートクラスタ/サイトへのレプリケーションに参加する。
Lazan
- ADS(Acropolis Dynamic Scheduling)によるホットスポット回避の機能を提供。
- 15分毎に監視を行い、AHVのCPU使用率が85%以上継続している状態が続いていた場合に、タスク(例:VMをCPU使用率の低い他のノードへライブマイグレーションする)を起動する。
Arithmos
- Nutanixクラスターの統計情報を集約するデータストア。
- Prism GUIとNutanix REST APIによって異なるコンポーネントから統計情報がArithmosに送信される。
Epsilon
- Prism Centralで動作しているサービスでLCMでもバージョン管理されているサービス。
- サービスが立ち上がらない場合が過去にありました。関連ドキュメントを張っておきます。

Nutanix Support & Insights
portal.nutanix.com

Nutanix Support & Insights
portal.nutanix.com
参考

Controller VM Components | Nutanix Community
Ever wondered what are some of the main services/components that make up Nutanix?The following is a simplified view of t...
next.nutanix.com

https://hyperhci.com/2019/05/24/nutanix-cluster-components-acropolis-services-explained/
hyperhci.com

分散DBシステム Apache Cassandraについて~その特徴と簡易インストール編~|【技業LOG】技術者が紹介するNTTPCのテクノロジー|【公式】NTTPC
NoSQLに分類されるデータベースの中において、人気の高いCassandraについて紹介します。
www.nttpc.co.jp

Nutanix Support & Insights
portal.nutanix.com

Use Nodetool | Apache Cassandra Documentation
cassandra.apache.org
Acropolis Dynamic Scheduling (ADS) | Nutanix Community
Acropolis Dynamic Scheduling (ADS) is responsible to examine the load on various components for hotspots and calculate w...
next.nutanix.com
コメント